


黑狐文字识别是一款基于先进OCR(光学字符识别)与AI技术开发的智能信息处理软件,专注于从图像、视频及音频等多模态数据源中高效、准确地提取并转换文字内容。其核心在于将非结构化的视觉或听觉信息转化为可编辑、可检索的数字化文本,支持包括JPG、PNG、PDF、MP4、AVI、MP3、WAV在内的广泛文件格式,简化了资料电子化、内容整理与信息复用的流程,适用于日常办公、学习研究、内容创作及专业文档处理等多种场景。
软件特色
多格式跨媒体识别
引擎具备强大的格式兼容性,能处理静态图像中的文字,还能直接解析视频帧画面或通过分享链接抓取在线视频内容进行文字提取,实现了从图片到动态视频的全覆盖文字信息捕获。
高精度结构化处理
针对身份证、财务票据、行业文档等具有固定版式的文件,内置了专项识别优化模型,能够有效排除复杂背景干扰,精准定位并提取关键字段信息,显著提升专业场景下的识别准确率与数据结构化程度。
音视频分离与转换
集成音轨提取能力,可将AVI、MOV、MP4等常见视频格式中的音频流无损分离,输出为MP3、M4A、WAV等独立音频文件;支持从音频文件中直接识别并生成文字字幕,打通了从听到到看到的信息链路。
批量化任务处理
设计有高效的批量操作界面,允许用户一次性导入数十甚至上百张图片或多个视频文件,系统自动排队进行顺序识别与处理,极大提升了处理海量资料时的整体工作效率,避免了重复性手动操作。
软件功能
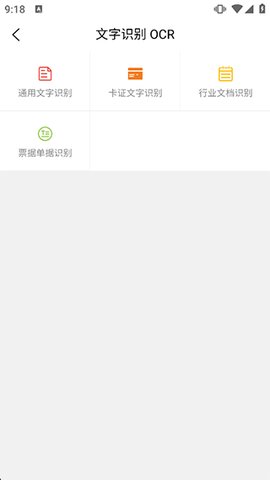
图文转换与编辑
核心功能是将图片中的印刷体或手写体文字转换为可自由编辑的文本格式。识别后的文字会呈现在编辑区域内,用户可直接进行校对、修改、复制或导出为TXT、DOC等格式文档,解决了从纸质资料到电子文档的快速数字化难题。
视频内容文字化
针对视频内容,能够逐帧分析或通过音频轨道识别,提取出视频内出现的所有文字信息或对话字幕。用户只需提供视频文件或网络视频的有效链接,即可获得完整的文字稿,便于内容复盘、字幕制作或快速检索关键信息点。
多格式音频转文本
支持处理WAV、MP3、FLAC、AAC等多种主流音频格式,运用语音识别技术将录音、讲座、会议记录等音频内容准确转换为文字记录。此功能特别适合媒体从业者、学生及需要整理录音资料的用户,实现了听觉信息的文本沉淀。
推荐理由
识别准确率卓越
得益于持续优化的AI算法,对印刷体文字的识别准确度极高,在日常使用中能保持稳定可靠的输出结果,有效减少了后期人工校对的工作量,确保了信息提取的可靠性。
操作流程极简化
交互逻辑清晰直观,从文件导入、功能选择到结果输出,整个流程步骤明确。即使是首次接触的用户,也能在无需查阅复杂指南的情况下快速上手,完成所需的识别或转换任务。
场景适配性强
满足通用文字识别需求,更针对证件、票据、合同等特定软件场景进行了深度优化,提供了专用模式。这种精细化设计使其在专业领域也能表现出色,拓宽了软件边界。
输出结果灵活实用
所有识别与转换的结果均提供即时编辑和多种导出选项。直接复制使用,也可以保存为文本文件,方便进一步整合到报告、文章或其他软件中,实现了信息流的无缝衔接。
相关问题
证件识别受边框干扰?
建议拍摄时确保证件主体充满画面,光线均匀。直接使用内置的证件识别专项模式,该模式会自动进行边缘检测与透视校正,有效裁剪并矫正画面,从而排除边框干扰,提升核心信息区域的识别精度。
视频链接提取为何失败?
提取失败可能源于链接不完整、来源平台暂未支持或网络连接不稳定。请检查链接是否完整复制,并确认其来自主流视频网站。若问题持续,可尝试刷新网络后重新粘贴链接,或直接下载视频文件至本地再进行识别。
批量识别图片顺序错乱?
在批量导入图片后,系统会进入预览管理界面。在此界面通过长按并拖动图片缩略图的方式,自由调整所有待识别图片的先后顺序,确保最终生成的文本顺序符合预期,实现有序的批量处理。
如何保存提取的音频?
在视频转音频功能中,选择目标视频文件后,会提供MP3、M4A等输出格式选项。选择所需格式,点击转换,完成后即可在输出目录中找到生成的独立音频文件,可直接用于播放或后续编辑。
















