


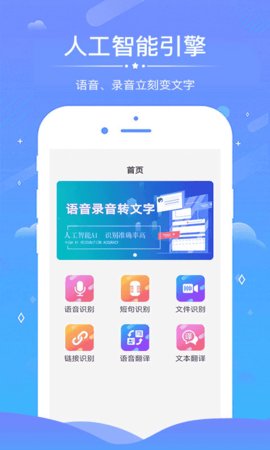

语音录音转文字是一款集成语音识别、多语言翻译与文本编辑功能的智能处理软件,能够将实时录音、本地音频文件或网络音频流高效转换为可编辑的文本内容。其采用先进的声学模型与自然语言处理技术,在保证高准确率的支持会议记录、课堂学习、媒体访谈及跨语言沟通等多种软件场景,显著提升信息处理与知识管理的效率。
软件特色
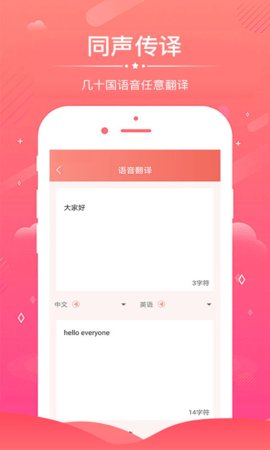
实时转写与同步翻译
在录音过程中,系统能够即时将语音流转化为文字并显示于界面,可一键启动翻译功能,实现源语言与目标语言文本的同步呈现,极大提升了跨语言交流与内容生产的流畅度。
多格式音频文件兼容
支持导入包括MP3、WAV、M4A、AAC在内的多种主流音频格式,用户可直接上传已录制的文件进行批量文字转换,扩展了素材来源与软件灵活性。
智能语种自动侦测
启动语音输入时,引擎能够自动分析并识别当前语音所使用的语种,无需用户手动选择和切换识别模型,简化了操作步骤,尤其适合多语混杂的交流环境。
文本深度编辑与多格式导出
识别生成的文本内容可在内置编辑器中进行细致的校对、润色与排版,并支持导出为TXT、DOCX、PDF等多种通用文档格式,便于后续的存档、分享或进一步加工。
软件功能
多说话人分离与标识
针对多人对话场景,如会议或访谈,系统能够基于声纹特征区分不同发言者,并在生成的文本中自动标注说话人角色,使会议纪要或采访稿的整理结构清晰、归属明确。
时间戳文稿自动生成
转换完成的文本可自动嵌入对应的时间戳信息,用户通过点击文本中的时间点,即可快速定位并回听原始录音中的特定片段,方便内容核查与重点回溯。
后台持续录音转写
即使在切换至其他手机软件或锁屏状态下,录音与文字转换进程仍可在系统后台持续运行,确保长时间访谈、讲座等内容能够被完整捕捉,不中断信息记录。
长音频智能分段处理
面对长时间的录音文件,系统可依据静音区间自动将其分割为多个逻辑段落,并分别进行识别处理。此方式提升了长音频的整体处理速度,也使得后续的文本编辑与内容管理更为便捷。
推荐理由
高鲁棒性识别引擎
核心语音识别模型经过大规模多场景数据训练,对各类地方口音、专业术语以及存在环境噪声的录音均有较强的适应性与辨识精度,保障了复杂条件下的转写可用性。
流畅直观的交互体验
用户界面逻辑清晰,从录音启动、文件导入到文本编辑与导出,核心功能路径直接,极大降低了用户的学习与适应成本,实现快速上手与高效产出。
兼顾效率与隐私的数据处理策略
采用本地预处理与云端智能引擎协同的工作模式,在确保识别速度与准确度的对音频及文本数据进行加密传输与处理,尊重并保护用户的数据隐私安全。
集成化轻量文档处理
除核心的转写与翻译功能外,还内置了文本合并、格式调整、重点标注等基础编辑工具,形成了一个从语音输入到文本成品输出的完整工作流闭环,减少在不同软件间切换的繁琐。
相关问题
如何开始一次实时录音转写?
进入软件主界面,点击中央的圆形录音按钮即可开始讲话,系统会实时将语音转为文字显示在屏幕上。录音结束后,文本会自动保存至历史记录,可供即时编辑或导出。
能否处理手机里已有的录音文件?
可以。通过主界面的文件导入功能,能够从设备存储空间中选择MP3、M4A等格式的音频文件。上传后,系统会自动完成识别,生成可编辑的文本。
翻译功能如何使用?
在语音转写完成后或编辑文本时,找到翻译选项,选择您需要的目标语言(将中文翻译为英文),系统会迅速生成翻译结果,并支持原文与译文对照查看。
识别后的文本如何保存或分享?
在文本编辑页面,使用导出功能,可以根据需要选择将内容保存为TXT纯文本、Word文档或PDF文件。生成的文件可存储在本地,或直接分享至其他社交与办公软件。
从哪里可以获得软件?
您可以通过本站提供的官方或可信渠道链接进行下载与安装。建议下载前核对版本信息,以确保获得最新、最稳定的功能体验。

















