
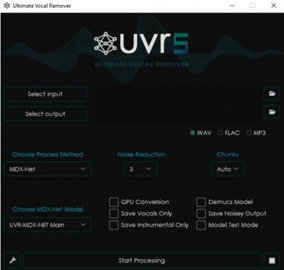
UVR5伴奏提取工具是一款基于深度学习的音频处理软件,能够高效地将音乐文件中的伴奏与人声进行分离。利用先进的神经网络模型,对输入的音频进行智能分析,实现高质量的音轨分离效果。软件主要面向音乐制作人、内容创作者及音频爱好者,提供了一种便捷的音频后期处理软件。其核心算法经过优化,平衡处理速度与分离精度,以满足不同场景下的专业需求。
软件特色
先进的分离算法
p>采用最新的深度神经网络架构,针对复杂混音环境进行训练,确保人声与伴奏分离的清晰度和保真度。GPU加速处理
深度整合NVIDIA CUDA计算技术,充分利用显卡的并行计算能力,大幅提升音频分离的处理速度。
内置丰富模型
软件预置了多个针对不同音乐风格和分离需求训练的专业模型,用户无需额外配置即可开始工作。
格式兼容广泛
通过集成FFmpeg与Sox音频处理库,支持包括MP3、FLAC、WAV在内的多种常见音频格式的输入与输出。
软件功能
高质量人声消除
能够精准地从完整歌曲中移除人声部分,生成纯净的伴奏音轨,适用于卡拉OK制作或音乐重混。
伴奏智能提取
反向操作,专门提取歌曲中的人声音轨,便于进行语音分析、翻唱练习或采样制作。
模型动态管理
提供便捷的模型下载与管理界面,根据音频特性选择或更新更合适的分离模型,以获得最佳效果。
推荐理由
分离效果出众
在同类工具中,其分离的精细度和残留度控制表现优异,尤其在处理现代流行音乐时效果显著。
p>处理效率极高依托GPU硬件加速,即使是较长的音频文件也能在短时间内完成处理,节省大量等待时间。
开源社区支持
作为开源项目,持续有开发者贡献新的模型和优化,软件功能与性能得以不断进化。
专业级软件免费
提供了通常需付费才能获得的专业级音频分离能力,且无任何功能限制,对个人用户极为友好。
相关问题
对电脑配置有何要求?
建议在Windows 10及以上系统运行,并配备支持CUDA的NVIDIA显卡(如GTX/RTX系列)以获得加速。显存8GB或以上能更好处理高精度模型。
如何处理非WAV格式文件?
软件内部集成了FFmpeg,可自动解码MP3、FLAC等格式。用户只需直接导入文件,分离完成后可选择输出为多种常见格式。
没有NVIDIA显卡能否使用?
可以。软件支持CPU模式进行分离,但处理速度会显著慢于GPU加速模式。对于短音频或非紧急任务,CPU模式仍可胜任。
如何获取和更新分离模型?
在软件主界面的设置或模型管理选项中,可以直接连接到模型服务器浏览并下载。本站也提供了完整的模型包与更新指南。

















